包含连续和离散值决策树的建立及可视化——ID3自建函数版

本文将手把手从信息熵的计算到决策树的可视化,逐步编写python代码来完成。
数据来源:西瓜书P84表4.3(文章末尾附)
ID3(Iterative Dichotomiser 3)算法是由Ross Quinlan在1986年提出的一种用于生成决策树的算法。它是决策树学习中最早的算法之一,以其简单易懂和高效的性能广泛应用于分类问题。D3算法的核心是特征选择,它使用信息增益(Information Gain)来选择特征。信息增益衡量的是通过选择某一特征来减少不确定性的程度,计算方式如下:
1.信息熵(Entropy):
信息熵是用来度量一个随机变量的不确定性或随机性。随机变量的不确定性越大,其熵值越高;反之,熵值越低。
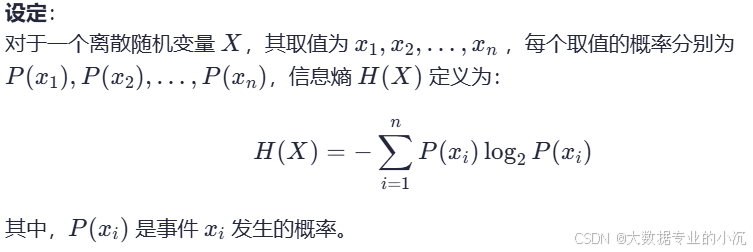
性质:
- 当所有事件的概率相等时,熵最大。例如,对于两个类别均等(各占50%)的情况,其熵为最大值(1比特)。
- 如果某一事件的概率为1(确定发生),则熵为0,表示没有不确定性
2.信息增益(Information Gain):
定义:信息增益是衡量在已知某个特征的条件下,随机变量的不确定性减少了多少。信息增益越高,表明该特征越能有效地减少不确定性,通常用于选择最佳特征(例如在决策树的构建中)。
 ID3算法会计算所有特征的信息增益,并选择信息增益最大的特征进行划分。
ID3算法会计算所有特征的信息增益,并选择信息增益最大的特征进行划分。
3.连续值处理(二分法)


4.graphviz库
Graphviz 是一个开源图形可视化软件,主要用于绘制图形、流程图和网络图。它在研究、计算机科学和工程领域得到广泛应用,特别是在数据结构、算法、程序分析和流程建模等方面。Graphviz 通过描述性语言(DOT语言)来定义图形特征,然后生成可视化图像。
下载和安装:
找到自己对应版本下载即可,这里我选择的是:

直接安装即可,注意在这里加上添加path:
 ,也可以手动配置path,在高级系统设置--环境变量--系统变量里,找到path添加上graphviz和安装地址即可。再在pycharm里找到Python Interpreter--Package搜索graphviz选择一个合适的源下载即可:
,也可以手动配置path,在高级系统设置--环境变量--系统变量里,找到path添加上graphviz和安装地址即可。再在pycharm里找到Python Interpreter--Package搜索graphviz选择一个合适的源下载即可:
 ,而后重启pycharm,可能要重启电脑,本人是在重启电脑之后才在终端输入dot -version看到安装信息的:
,而后重启pycharm,可能要重启电脑,本人是在重启电脑之后才在终端输入dot -version看到安装信息的:
至此graphviz安装完成,简单测试一下:
得到如下.png文件:
1.计算信息熵
我们定义一个get_entropy函数,目的是计算给定特征的熵
- :通常是一个 ,包含数据集。
- :一个指定要计算熵的特征列名。
- 初始化为 0。它将存储最终计算的熵值。
- 计算特征中每个唯一值的出现次数。
2.计算信息增益
对于信息增益的计算,要考虑两种情况:离散值如“清晰”、“稍糊”,连续值如0.679、0.774
对于离散值,直接计算出现的频率作为概率即可,我们构建一个get_gain_disperse函数,
一样是传入data和feature两个参数,这里就不赘述:
- 对于每个特征值,筛选出相关的子数据集 。
- 通过 计算该子集的信息熵,并根据其在原数据集中所占的比例加权累加到 中。
- 计算原数据集中 的信息熵,并用它减去 ,最终得到信息增益。
- 提前设置好阈值给后面连续值阈值的计算铺路,方便后面统一封装。
对于连续值,使用二分法将数据集划分为两大类,每次划分的标准Ta为排序之后相邻两次的数据均值,这些Ta中算出的信息增益最大值,即为对应的阈值,我们构建get_gain_continuous函数,传参不变,feature需为连续值的列名:
- 用于存储所有可能的阈值。
- 初始化为0,用于跟踪当前最大的增益。
- 也初始化为0,用于记录对应的最佳阈值。
- 提取特征和目标列,然后对特征值进行排序并重置索引。
- 对每个阈值 ,将数据分为两个子集:(特征值小于等于 )和 (特征值大于 )。
- 计算这两个子集的信息熵,并根据它们在整个数据集中所占的比例加权求和,得到 。
- 通过原始数据的熵减去加权后的熵,计算出信息增益。
- 如果当前的信息增益大于已记录的最大信息增益,则更新 及对应的 。
再将两个函数封装成一个函数,可处理离散值和连续值的get_gain:注意这里我加的if判断是直接根据数据集来定义的,十分简介但仅限这一个数据集,若需处理其他数据可以用其他方法处理如 库的 属性检查数据类型。
更泛用的处理:
3.获取最佳特征
我们构建get_best_feature函数,由于实验数据中包含离散值和连续值,故需加上判断。其中需要注意的是排序的lambda函数选择,需按照信息增益(优先)和阈值(次之)的规则来排序否则可能会出现两个结点相同的现象:
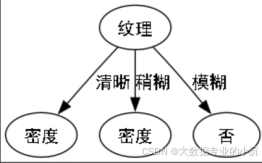 ,但是在将整个实验完成之后我尝试修改回去后又跑了一遍,我发现生成的决策树并没有什么变化,猜想是因为labels的改变与否或顺序重复什么的原因导致第二次划分的时候本不该出现的某个特征又未被去除,导致两个节点相同。
,但是在将整个实验完成之后我尝试修改回去后又跑了一遍,我发现生成的决策树并没有什么变化,猜想是因为labels的改变与否或顺序重复什么的原因导致第二次划分的时候本不该出现的某个特征又未被去除,导致两个节点相同。
4.构建决策树
我们构建build_tree函数,其中的三个参数:
- :输入的数据集,包含特征和目标变量(如是否好瓜)。
- :可选的特征标签列表,用于选择最佳分割特征。
- :当前递归的深度,默认为0,便于调试实际上没什么意义。
基本采用递归的思想,将每一级中间结点当作父节点,直到叶子节点,或以下情况:
- 如果数据为空 (),返回 ,停止递归。
- 如果数据集中只有一个类别,直接返回该类别。
- 如果没有特征可以选择,返回数据集中频率最高的类别。
其中依然要考虑离散值和连续值,通过阈值判断,为0则表示为离散值,对该特征的每个取值进行分割,递归构建相应的子树;阈值大于0,则将数据分割为两部分:小于等于阈值和大于阈值,递归构建子树。
此时要注意到由于代码逻辑不是很直接将子树通过键值对的方式直接链接到父节点那,而是在最外一层的字典内存储,故还需要将tree_node的结构再进一步完善。
这里采用手动处理的方式(后续可能会完善直接构建函数完成):
至此决策树的结构构建完成:
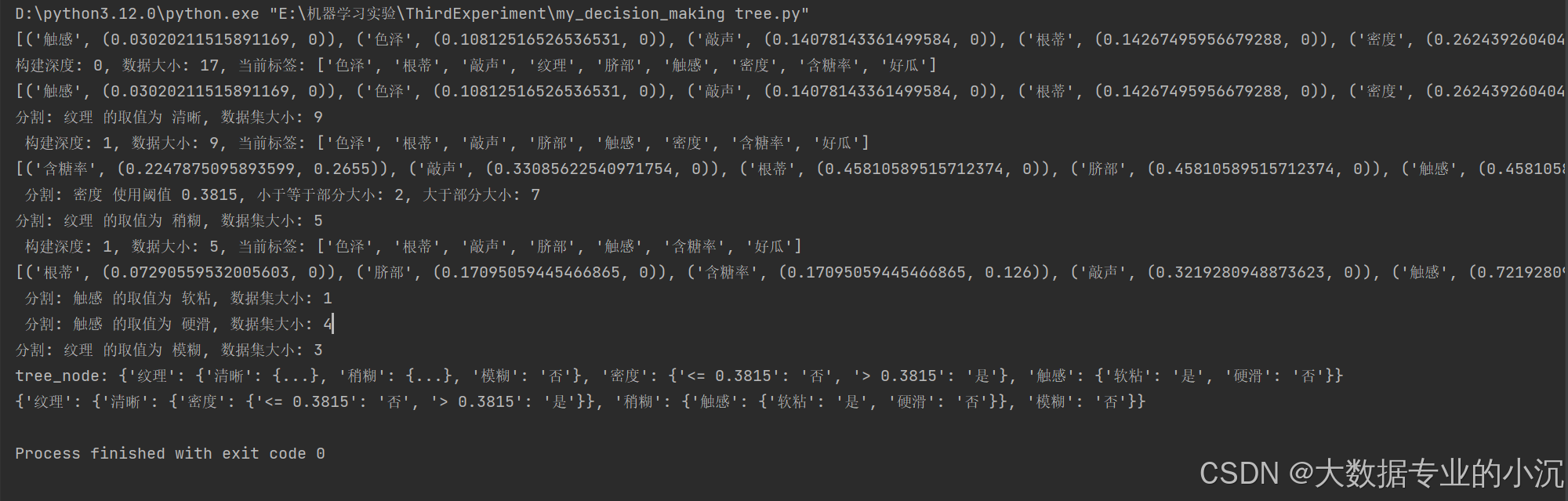
4.创建dot对象
我们创建add_edges函数包含三个参数:
- : 一个 Graphviz 图形对象,表示创建的图形。
- : 父节点的名称,用于表示当前节点的父亲。
- : 字典型数据,包含待添加的节点和边,树的结构由此数据决定。
其中须注意的有:
①字典的.keys()和.values()返回的是一个可迭代对象无法直接使用,需要先将其转为列表才能调用。而循环的第一步就是判断是否为字典。
②dot.node()的第一个参数是结点的ID而第二个参数是标签即展示在图例中的字符串,在处理叶子节点,即指向好瓜与坏瓜时,要将每个结点的ID设为不同值,这里用父节点来命名就能保证每次指向的好瓜或者坏瓜是独立的了:
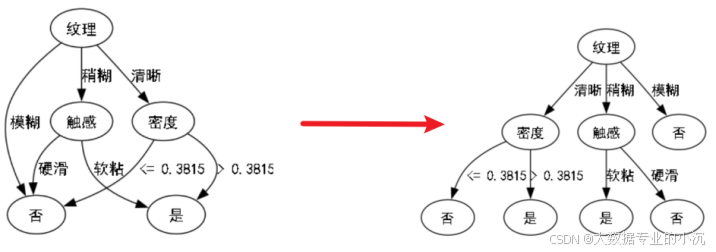
③中文乱码问题:
调用上面已经构建完成的函数,整理逻辑,先初始化一个根节点,调用add_edges函数,设置中文字体,最后将构建的dot对象输出成png格式。
源码
数据集(data.csv)
编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.460,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是 3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是 4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是 5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是 6,青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是 7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是 8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是 9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否 10,青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否 11,浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否 12,浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否 13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否 14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否 15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.360,0.370,否 16,浅白,蜷缩,浊响,模糊,平坦,软粘,0.593,0.042,否 17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否
参考运行结果
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.ksxb.net/tnews/4785.html


