PySpark3.4.4_基于StreamingContext实现网络字节流中英文分词词频累加统计结果保存到文本中

利用pyspark开发streamingContext程序,统计实时网络字节流数据,实现中英文分词统计,并将统计结果持久化保存到文本文件中
实现分词效果如下:
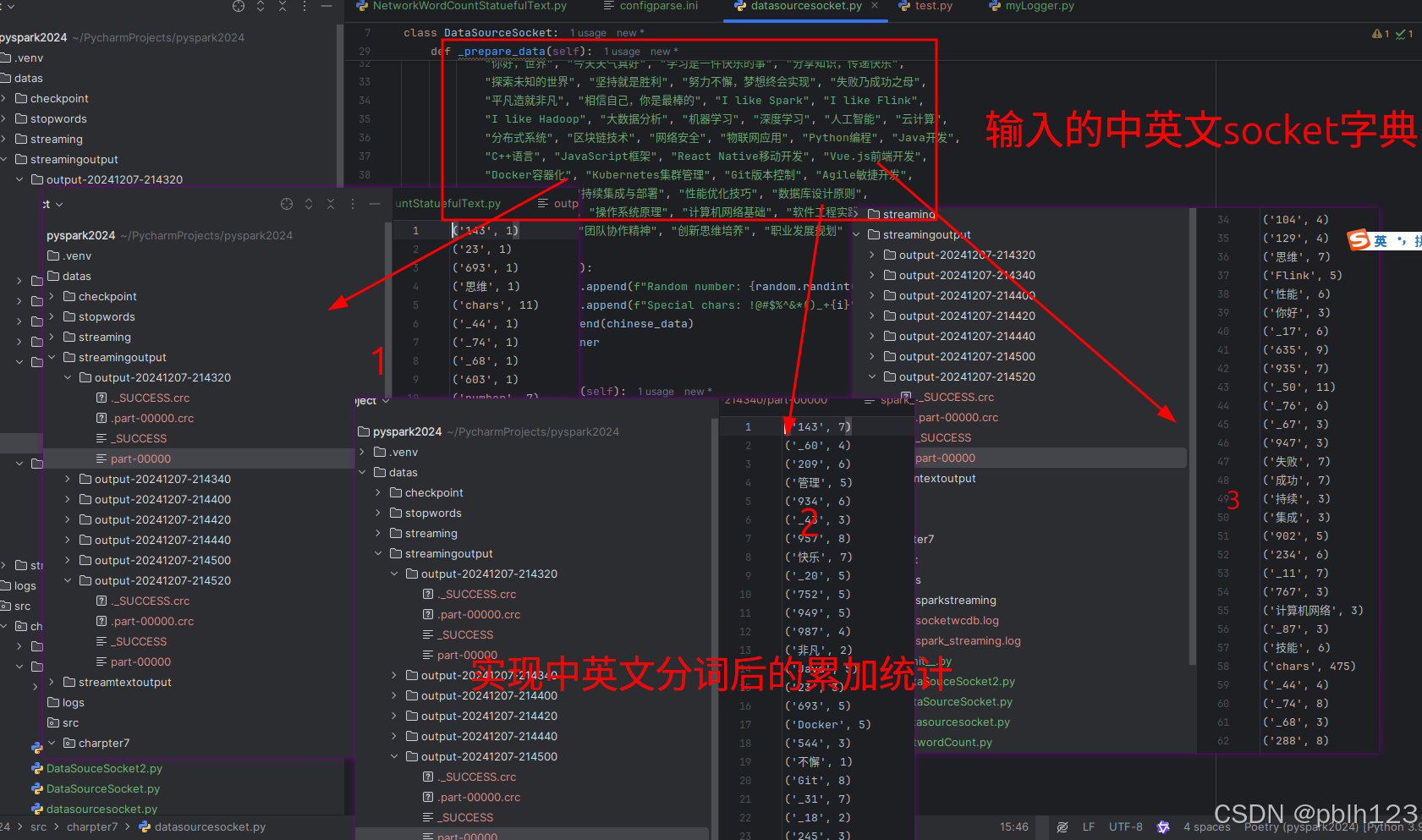
1. 开发datasourcesocket.py工具模拟生成socket字节流
2. 开发辅助类工具进行日志记录myLogger.py
3. 开发pysparkStreaming程序NetworkWordCountStatuefulText.py,实现中英文词频分词统计累加统计,并保存为文本
项目的代码结果如下:
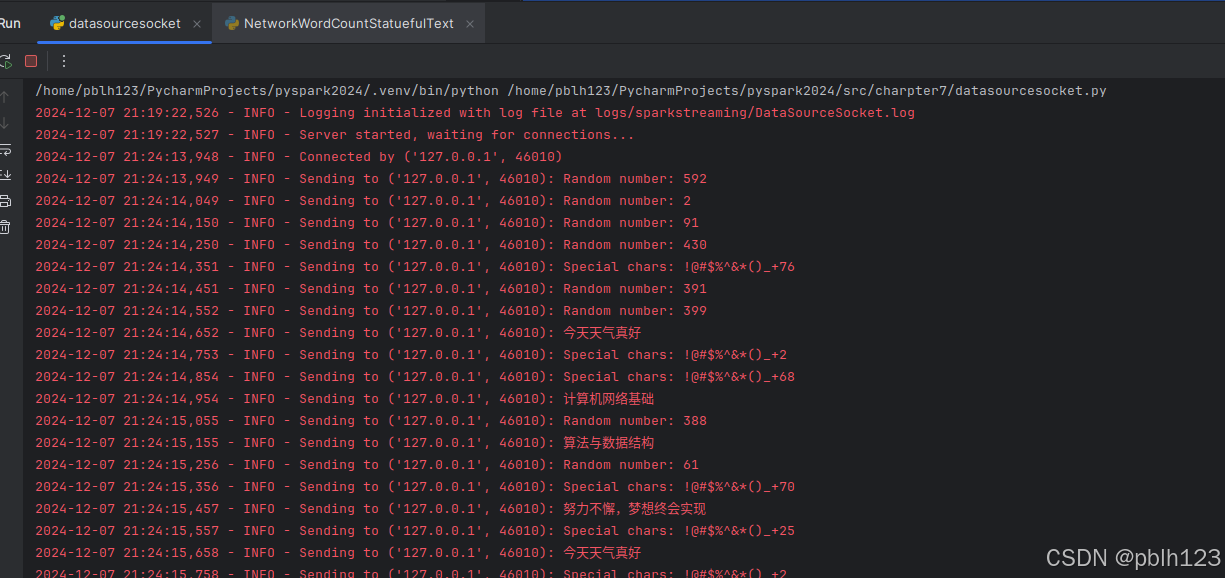
用pycharm开发datasourcesocket.py
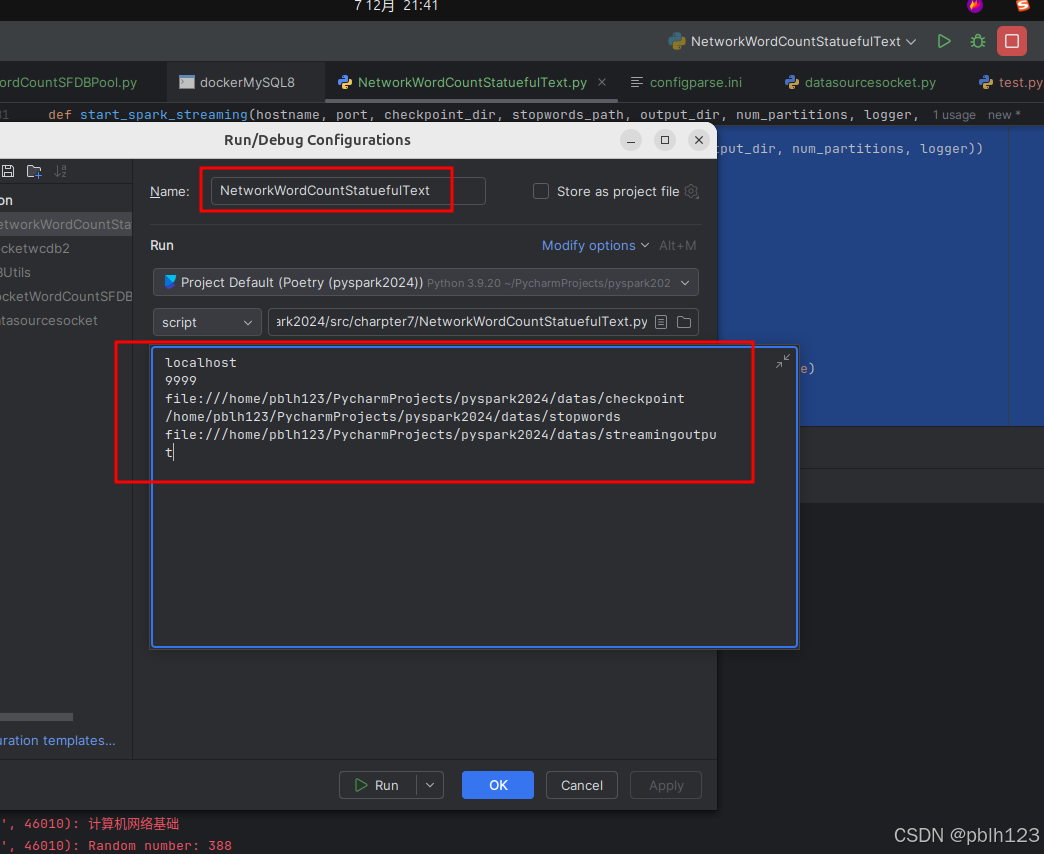
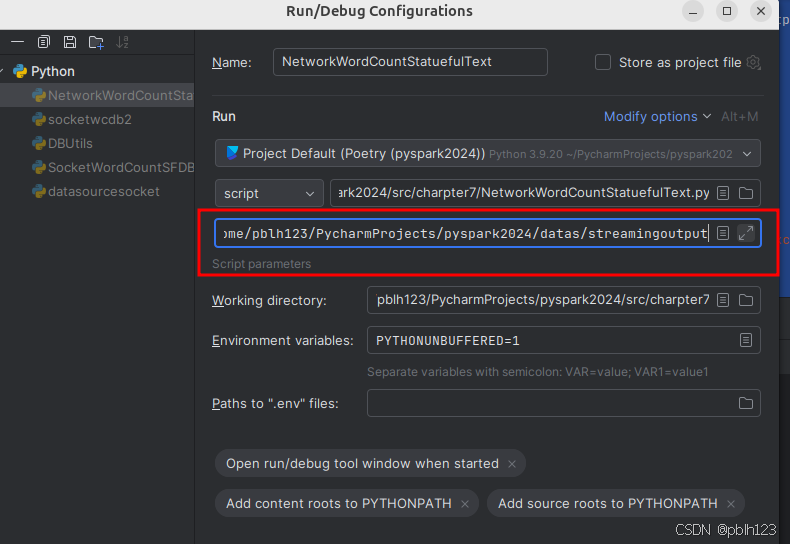
1. 配置运行参数
依据自己的环境修改配置路径
2. 运行程序
运行前检查路径,目标目录是空的

启动运行程序
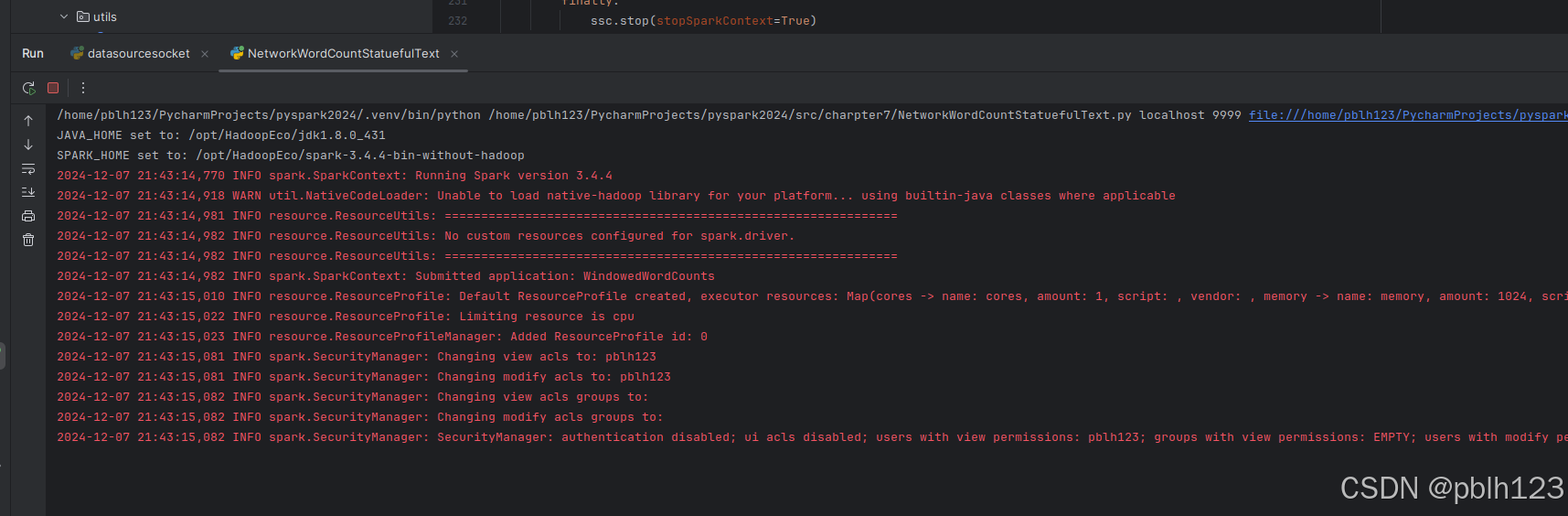
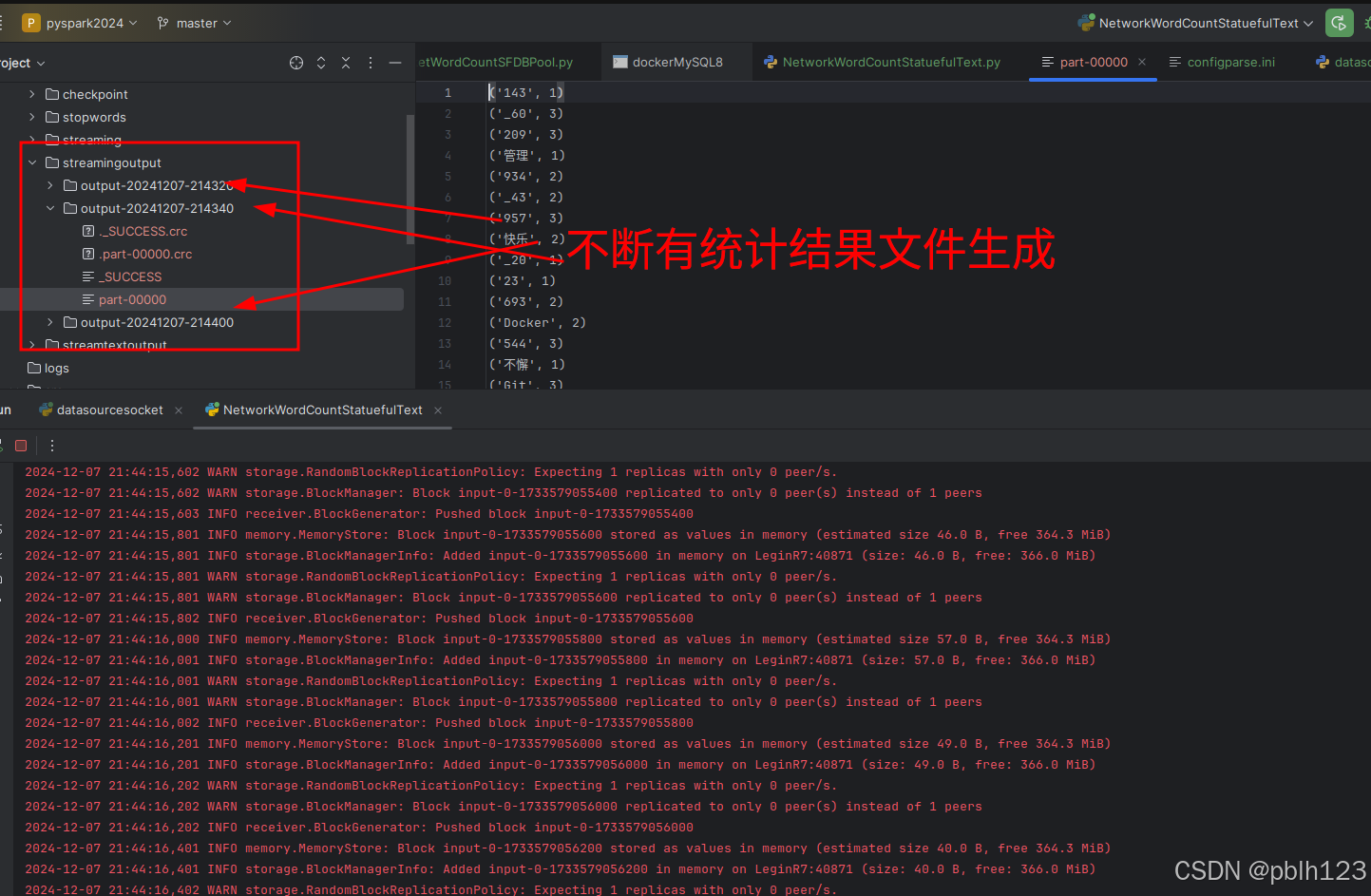
退出后,检查持久化的结果文件信息,查看中英混合分词统计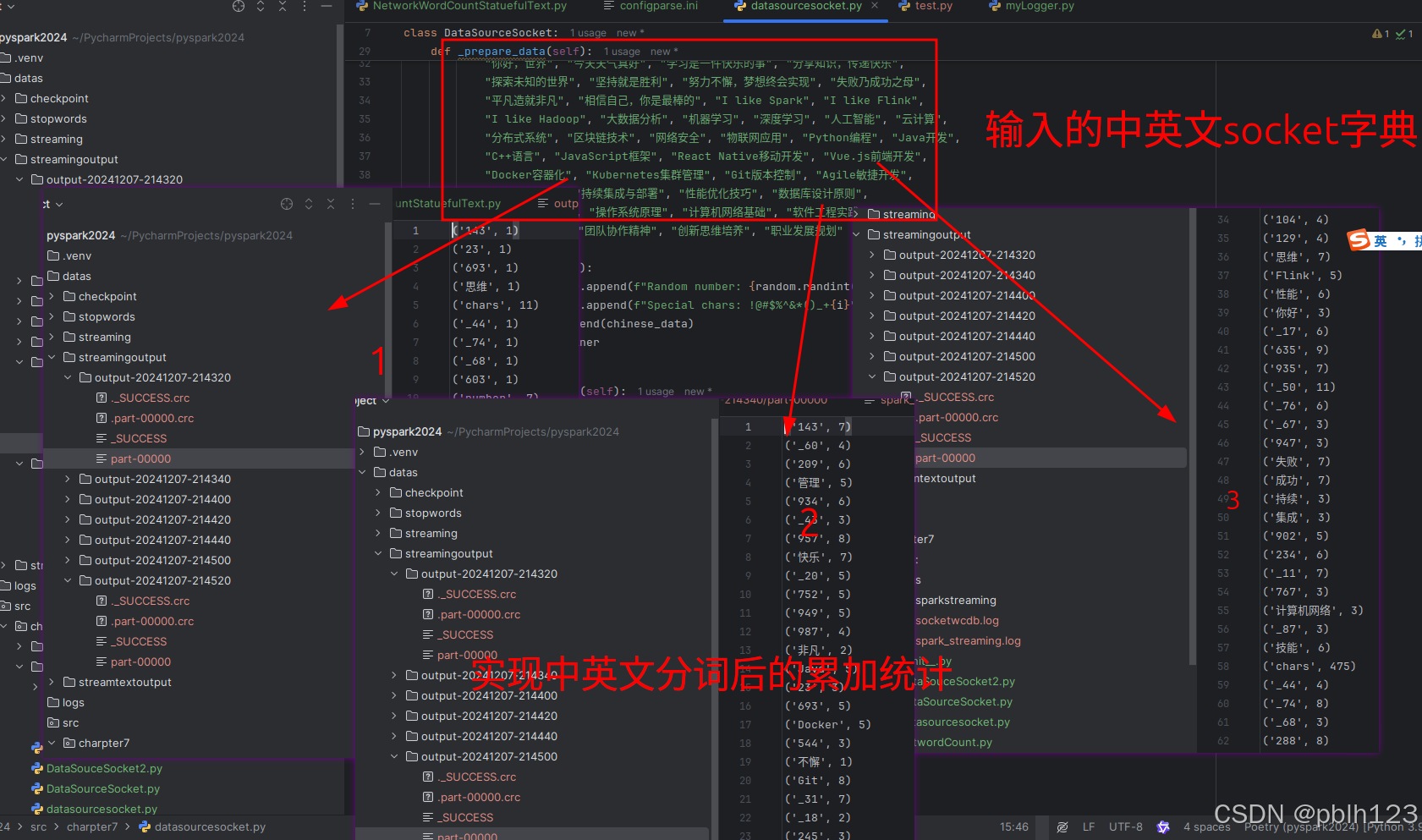
更多技术文档分享,讨论,欢迎关注微信公众号:
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.ksxb.net/tnews/2917.html
相关文章
-

万能电子书阅读器最新版本 v4.6.5 安卓版手机txt阅读器「万能电子书阅读器最新版本 v4.6.5 安卓版」
-

死神VS火影 v3.8.0.3最新版死神vs火影手机版「死神VS火影 v3.8.0.3最新版」
-

苹果手机如何滚动截屏 oppo手机怎么滚动截屏苹果手机怎么滚动截屏「苹果手机如何滚动截屏 oppo手机怎么滚动截屏」
-

邓家佳为什么接这种剧,超烂,一集都看不下去!高中可以带手机吗「邓家佳为什么接这种剧,超烂,一集都看不下去!」
-

诺基亚推出一款支持在家自我修复的智能手机诺基亚智能手机「诺基亚推出一款支持在家自我修复的智能手机」
-

不忘初心win10 22H2游戏版 19045.5131 x64无更新版windows10手机版「不忘初心win10 22H2游戏版 19045.5131 x64无更新版」
-

如何正确关闭蓝牙功能的详细步骤与注意事项蓝牙手机「如何正确关闭蓝牙功能的详细步骤与注意事项」
-

火热的二战游戏合集2023 必玩的5款二战游戏推荐二战游戏手机游戏「火热的二战游戏合集2023 必玩的5款二战游戏推荐」